Minimum number of images needed for each species
Published on: 19 December 2024
Abstract
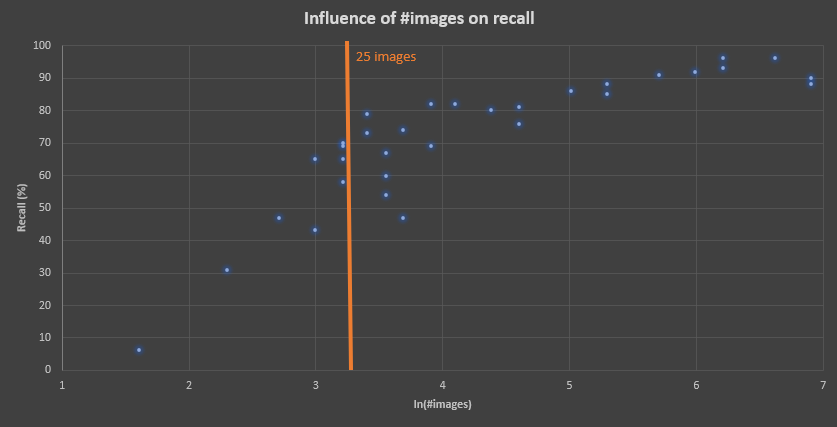
Convolutional Neural Networks (CNNs) have transformed image recognition and classification, delivering state-of-the-art results across various domains. However, the performance of CNN models significantly depends on the quantity and quality of the training data. In our analysis, we examined the relationship between the number of images per species and the model's recall performance. To strike a balance between achieving acceptable performance and mitigating the impact of omitting a species from the model, we established a threshold of at least 25 images per species.
Introduction
The performance of a CNN model is intricately linked to the number of images used in the training process. Generally, a larger and more diverse dataset leads to better performance, as the model can learn more robust and generalized features [1]. This is because CNNs learn by identifying patterns and features in the training data, and a larger dataset provides a more comprehensive representation of the underlying data distribution, allowing the model to learn more diverse and nuanced representations.
However, the relationship between image quantity and CNN performance is not always linear. While increasing the dataset size generally improves accuracy, there is a point of diminishing returns where adding more data provides only marginal gains. The optimal number of images required for training a CNN depends on several factors, including the complexity of the task, the variability within the dataset, the architecture of the CNN itself, and the number of classes [2].
When insufficient training data is available, CNN models are prone to overfitting. Overfitting occurs when the model learns the training data too well,
capturing noise and specific details that do not generalize to unseen examples. This results in poor performance on new data, as the model fails to recognize
the underlying patterns and features.
Limited data can also lead to class imbalance, where some classes have significantly fewer images than others. This imbalance can bias the model towards the
majority classes, resulting in poor performance on the minority classes. The impact of class imbalance can be particularly severe in real-world scenarios where
certain events or objects are inherently rare. Moreover, the influence of class imbalance on classification performance increases with the scale and
complexity of the task [3, 4].
Methods
We used the Harpa genus dataset for these tests. For species Harpa major, 1228 images are available. When all images are used to create a model, a recall of 0.92 was obtained. We have created a model with a varying number of images of Harpa major, while the number of images for the other species of the genus Harpa stays the same. The images included in the dataset were selected at random, as well as 100 images for a test dataset. For the training and validation dataset a 80-20 split was used.
Results
The figure below illustrates the relationship between the number of images of Harpa major and the recall metric.
Between 5 and 1000 images were included in the dataset to create a model to identify the species of the Harpa genus.
The dataset included 12 species, each represented by 38 to 833 images.
The amount of images in all classes stays the same for each run, only for Harpa major the number of images varies between
runs.
Discussion
The tradeoff between including a species in the dataset with a limited number of images and ensuring adequate model performance is critical, because a CNN model
will always identify a species, but often with a low probability for unknown species. Therefore a threshold of 25 images per species is decided
with is a good balance between model performance and species completeness.
It is important to note that these results may vary for other genera, as they depend on factors such as the total number of images, the type of seashells,
and image quality. Future studies should evaluate these variables to develop more generalized guidelines for dataset preparation.
References
- [1] geeksforgeeks. How Many Images per Class Are Sufficient for Training a CNN?. geeksforgeeks, 2024.
- [2] Brenton Adey. Investigating ML Model Accuracy as Training Size Increases. Telstra Purple, 2021
- [3] Mateusz Buda, Atsuto Maki, Maciej A. Mazurowski. A systematic study of the class imbalance problem in convolutional neural networksNeural Networks, 106:249–259, 2018
- [4] Moshe Davidian et al. Exploring the Interplay of Dataset Size and Imbalance on CNN Performance in Healthcare: Using X-rays to Identify COVID-19 Patients. Diagnostics (Basel). 2024 Aug 8;14(16):1727